Visualizing Gender Bias in Movie Reviews
The goal of this project is to highlight possible gender bias in film reviews in this data set. The underlying assumption is that bias may appear in a variety of ways, from lower scores or more negative reviews by male critics for films starring or directed by women, to the appearance of ”gendered” adjectives or word associations that may be inconsistent depending on the gender of the critic. There have been several movie reviews from the past year or more that have been called out for using sexist language and demeaning women, and there have been studies that have shown that male critics are usually harsher on movies starring women than female critics are. Read more about it here
Around 3000 reviews were collected from the New York Times, annotated for the gender of the director/lead actor, and analyzed in several ways for possible gender bias.
The reviews were divided into 8 subsets:
- Female critic reviews about female starring films (FcFa)
- Male critic reviews about female starring films (McFa)
- Female critic reviews about male starring films (FcMa)
- Male critic reviews about male starring films (McMa)
- … and similarly for female and male-directed films.
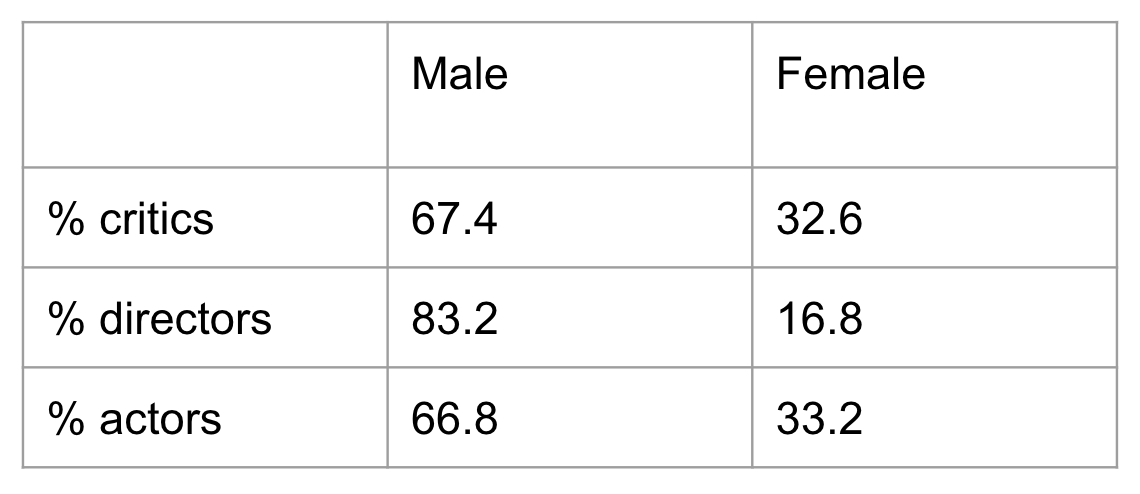
Metadata
Metadata refers to information about the data set in general. Some important facts about this data set:
- Around 3000 reviews total
- 924 reviews written by female critics
-
1903 reviews written by male critics
- 475 reviews about female-directed films
-
2352 reviews about male-directed films
- 653 reviews about male-starring films
- 1305 reviews about female-starring films
This translates to:
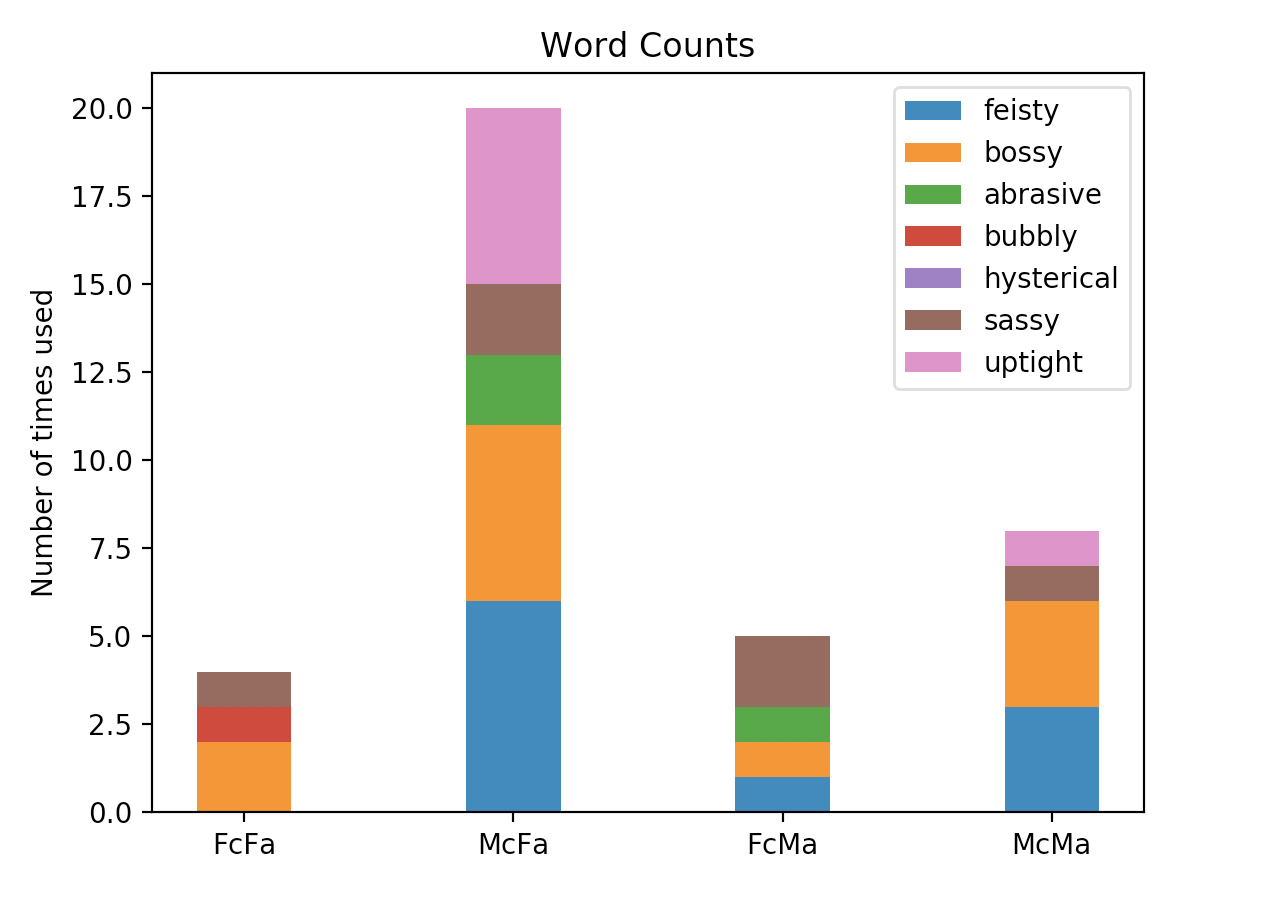
NLTK analysis
Python has a natural language processing tool called the Natural Language Toolkit, which has methods to count instances of certain words in text (as well as display their context). A list of words that are typically only used to describe females was counted in the subsets of data relating to actors, when they were used to describe women:
NLTK can also generate word clouds for sets of text, with words that are most frequent in the text appearing the largest.
Female critics, female star

Male critics, female star
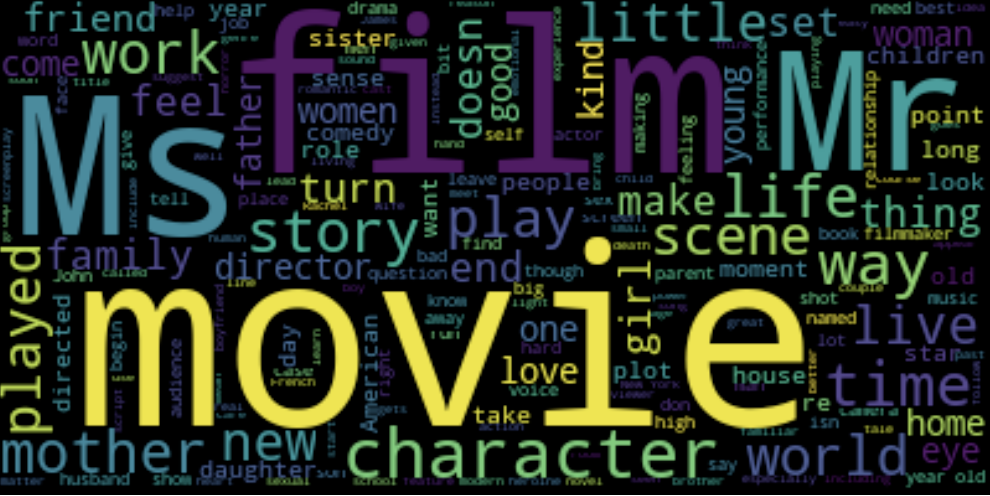
Female critics, male star
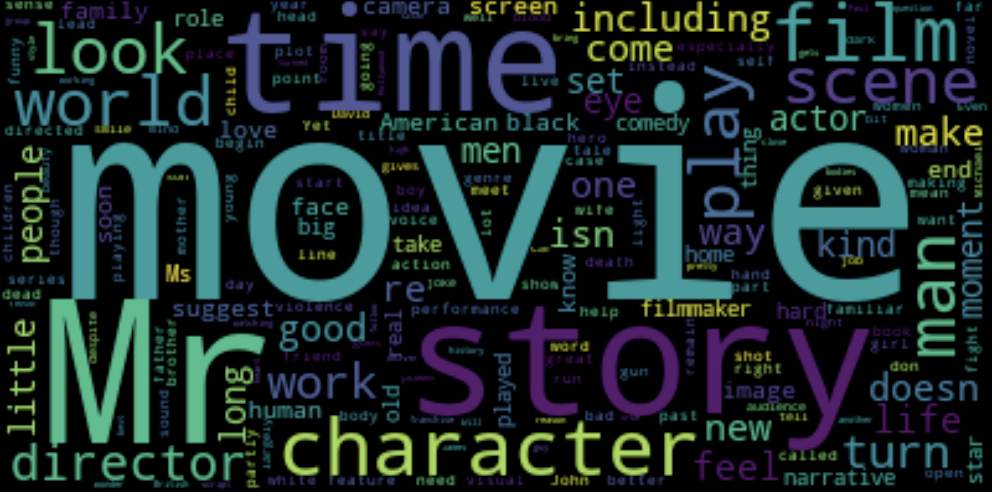
Male critics, male star
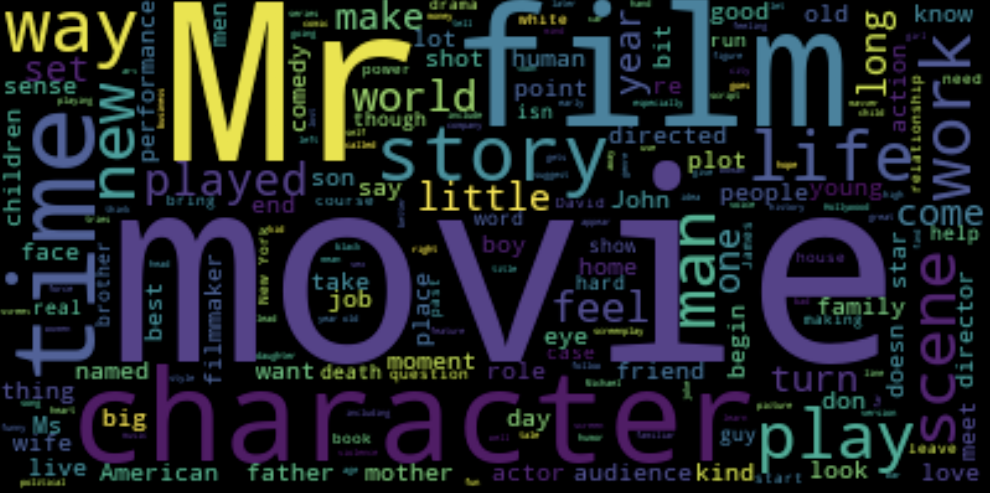
Female critics, female director

Male critics, female director

Female critics, male director

Male critics, male director
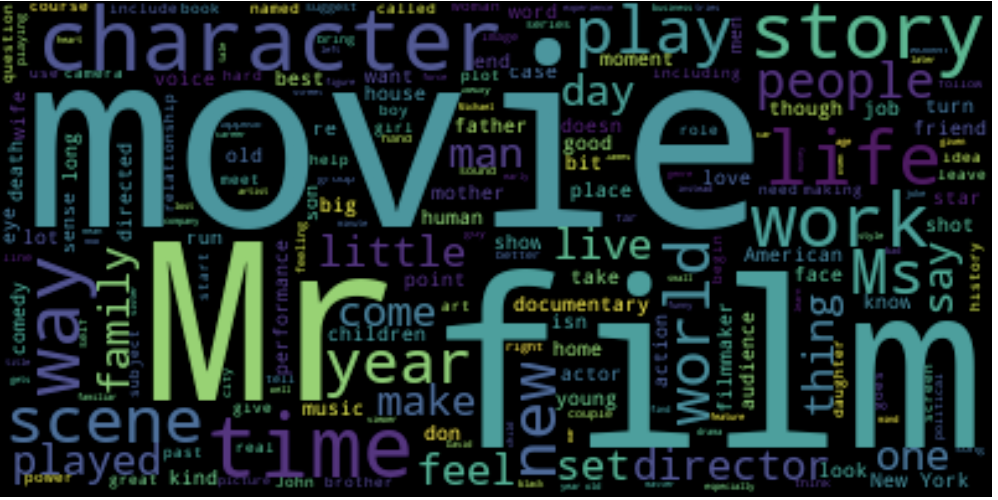
Word2Vec analysis
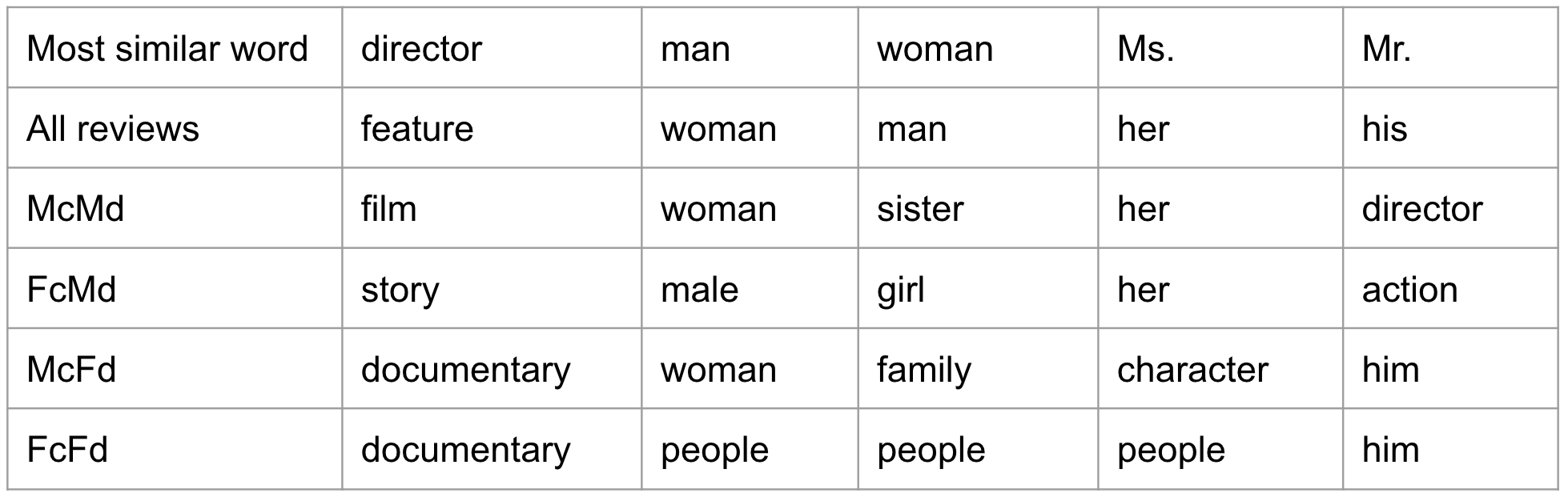
Word2Vec is a tool that, given a body of text to train on, will build vectors for the words in the text. With Word2Vec you can input a word and get the words most similar to that word based off the input body of text alone. This analysis was conducted separately on each of the 8 subsets of data described above (FcFa, McFa, etc.) The most similar words to the input words are shown below:
Most similar words for actor subsets:
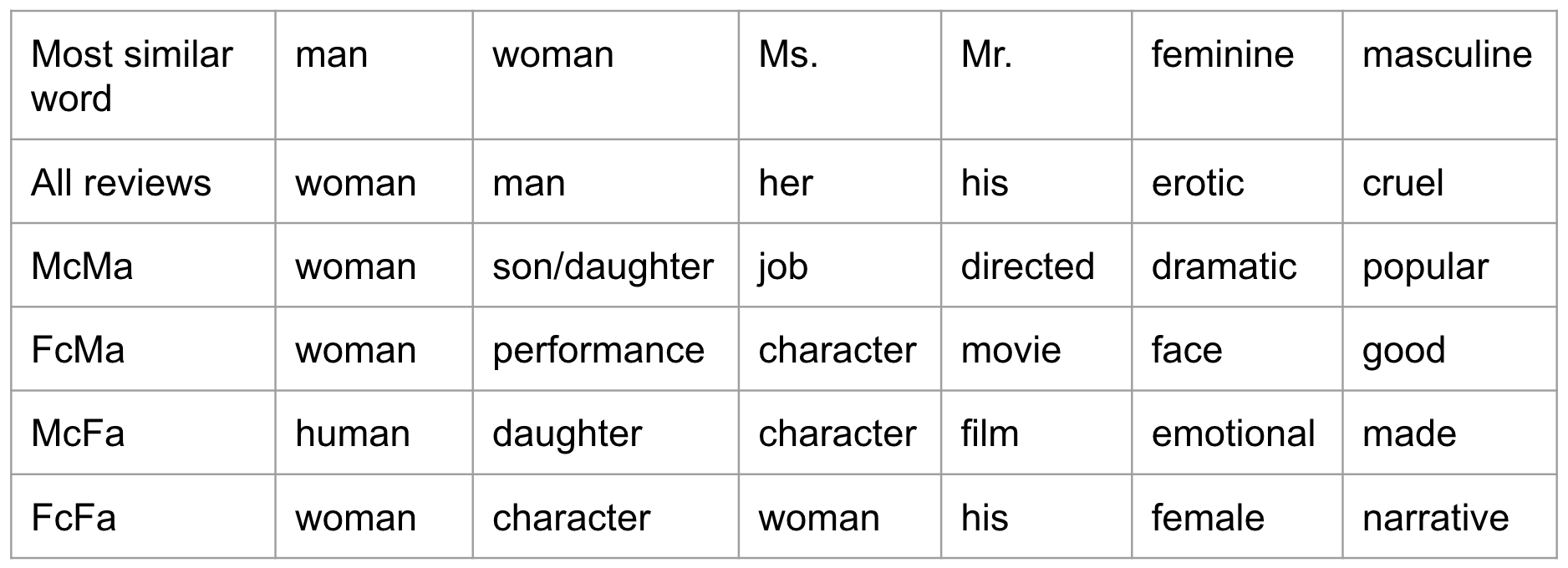
Results for most similar words for director subsets:
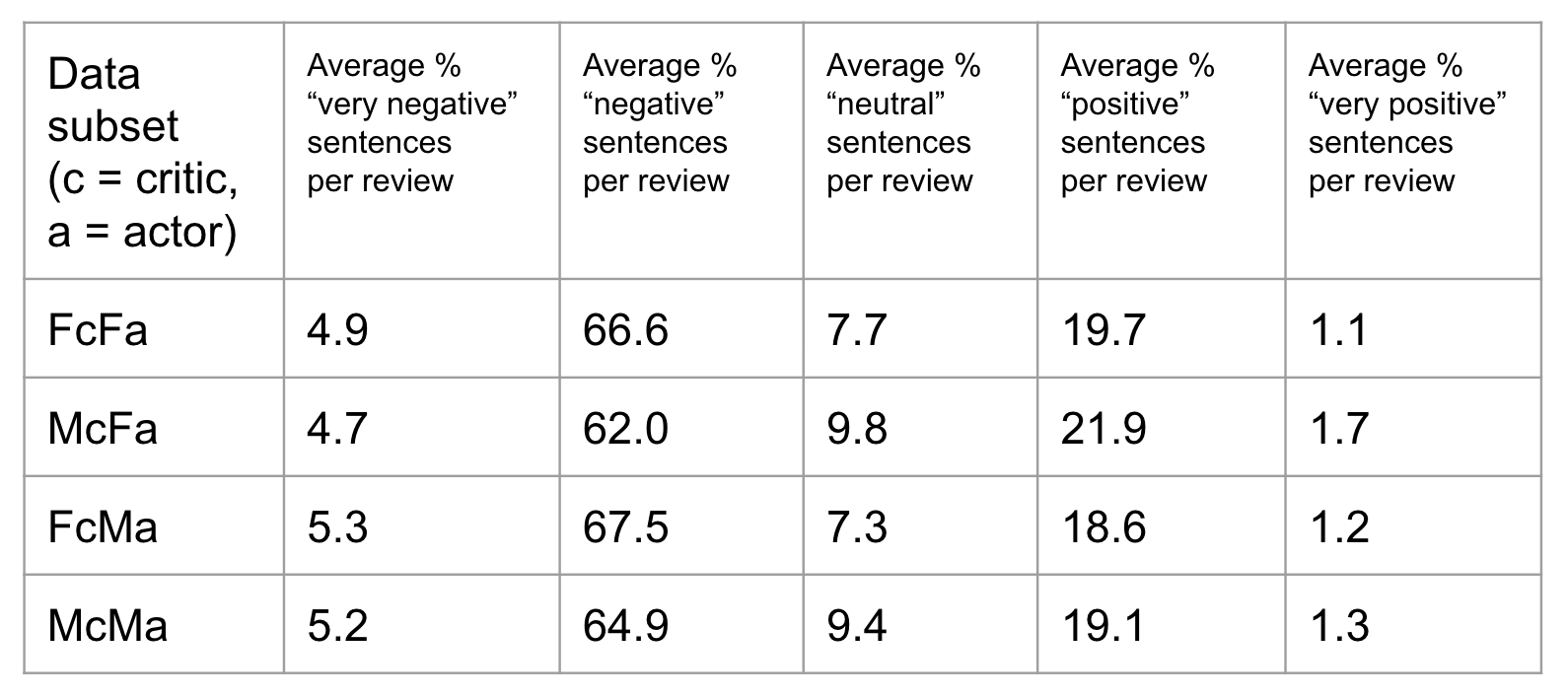
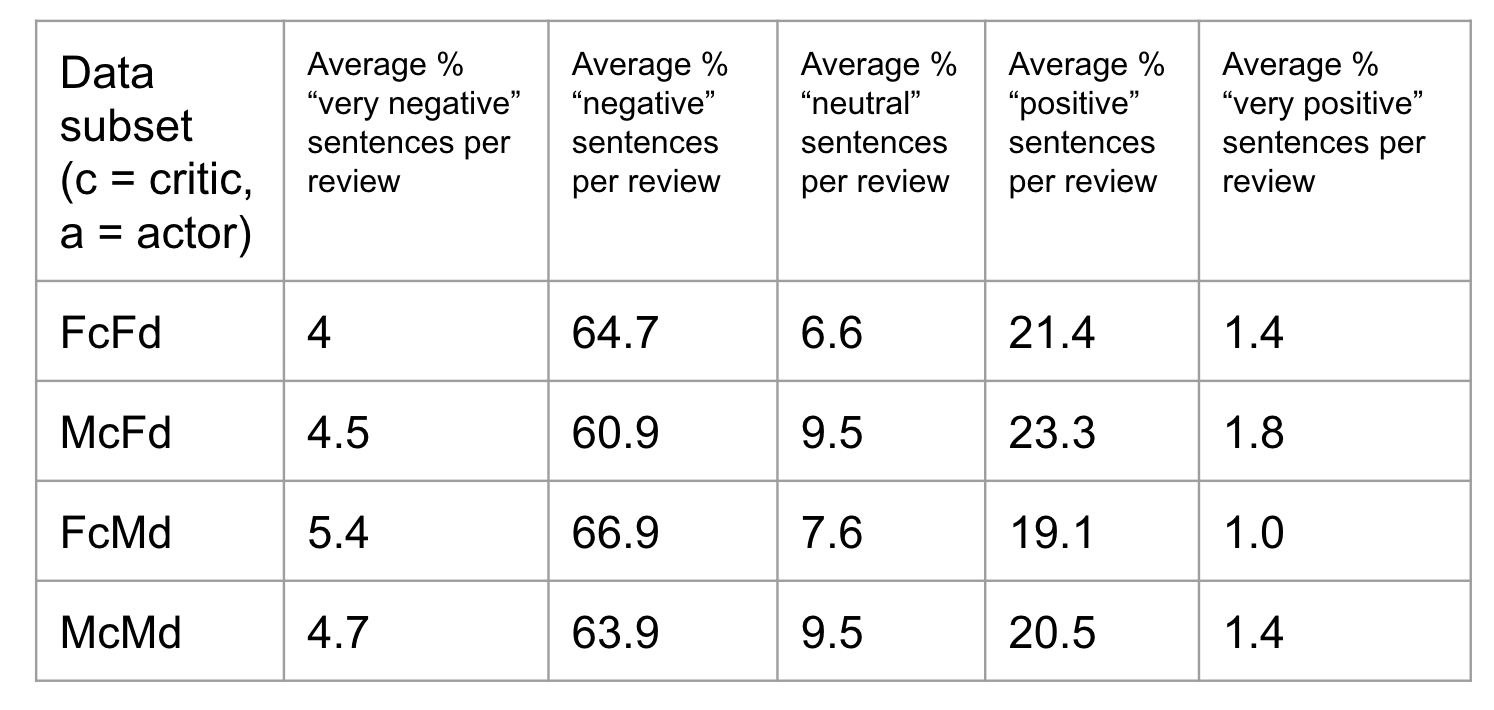
Sentiment analysis
The Stanford NLP lab created a tool that takes in a body of text and computes a sentiment and score for each sentence from 0-4. The values are “very negative”(0), “negative” (1), “neutral” (2), “positive” (3), “very positive” (4).
The graphs below plot the percentage of a review that is assigned each of these labels, for all of the reviews:
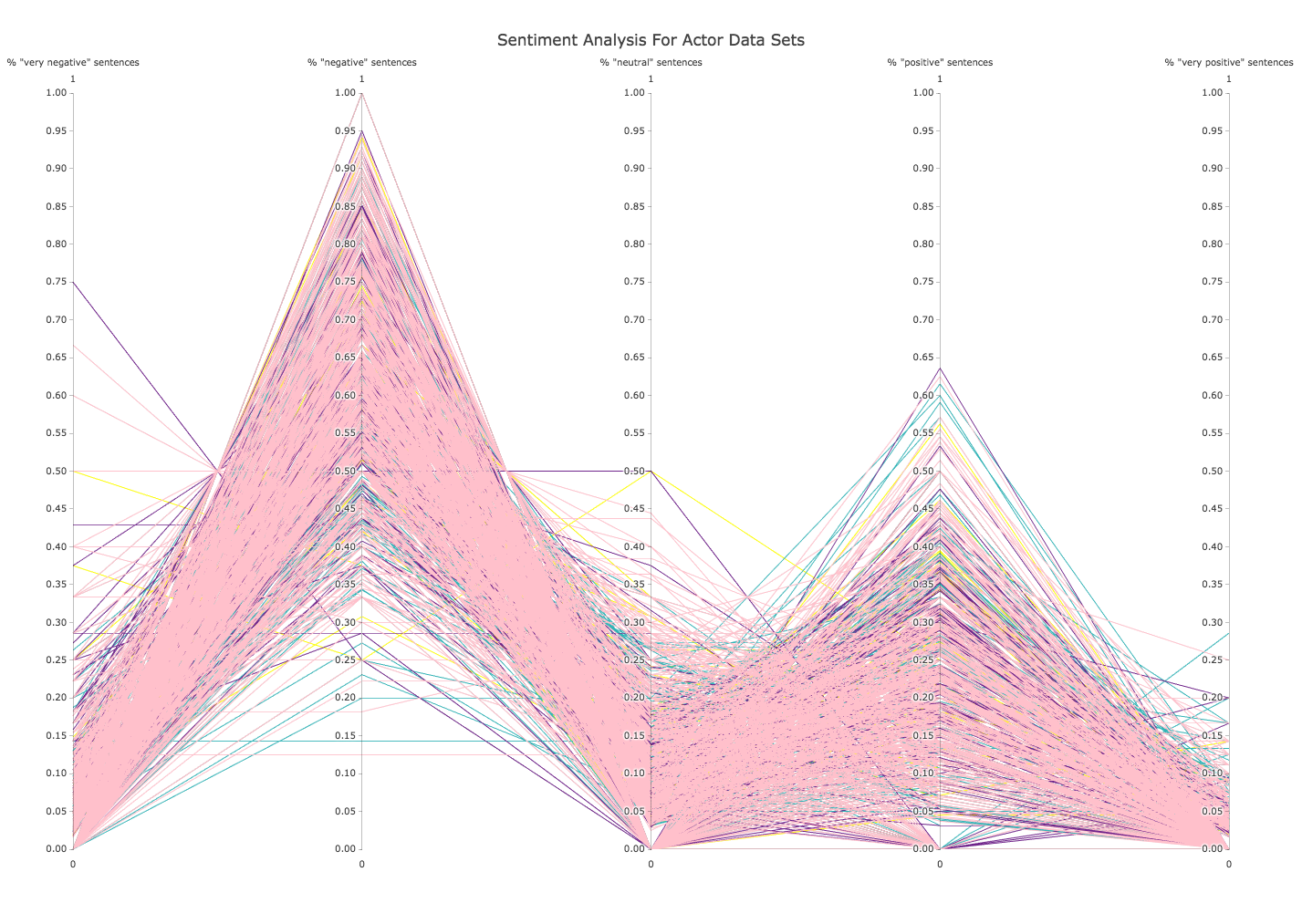
(yellow = FcFa, teal = McFa, purple = FcMa, pink = McMa)
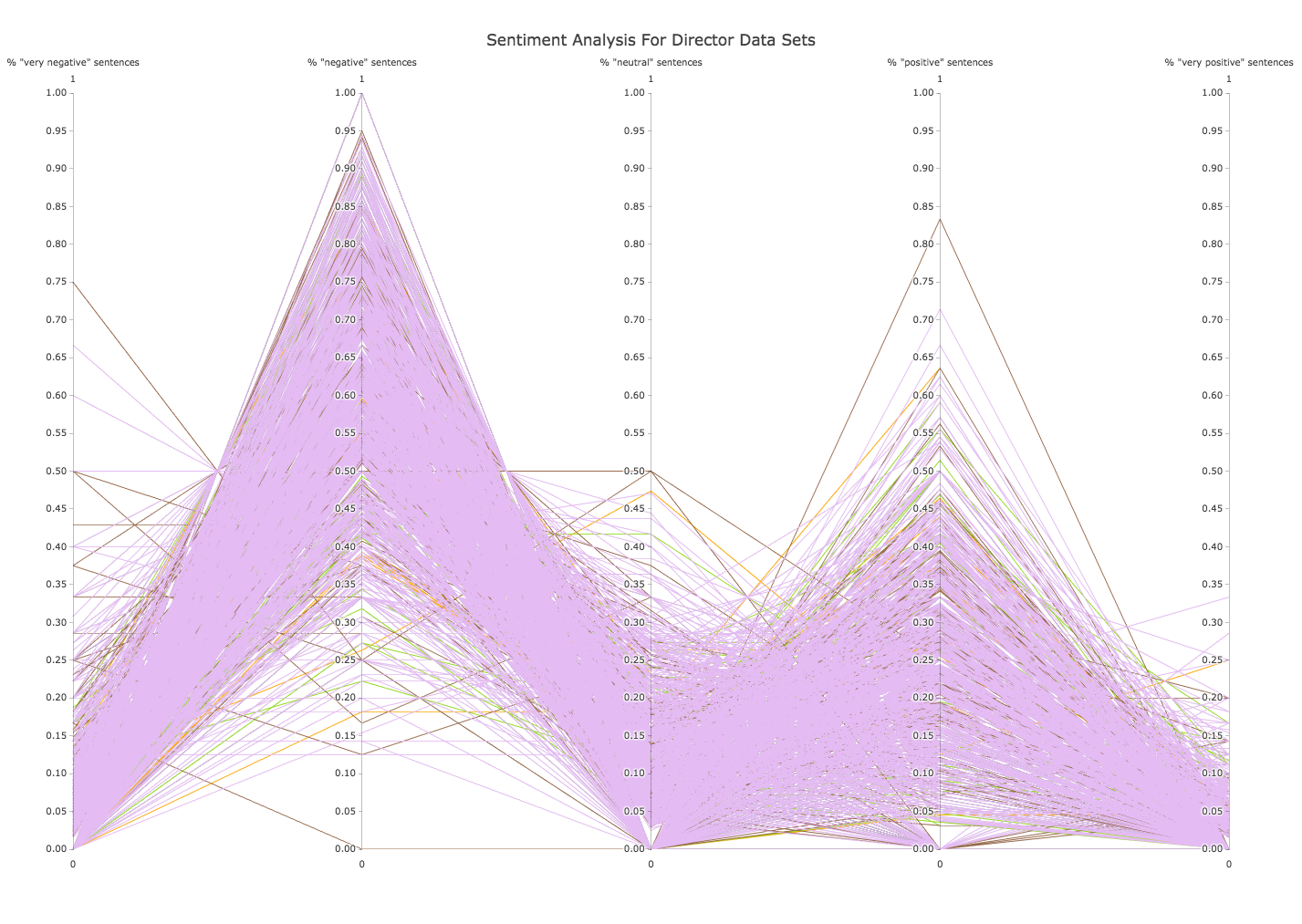
(orange = FcFa, green = McFa, maroon = FcMa, lilac = McMa)
The tables below show the average percentages of these labels for a review from each data subset: